We propose several different techniques to improve contrastive divergence training of energy-based models (EBMs). We first show that a gradient term neglected in the popular contrastive divergence formulation is both tractable to estimate and is important to avoid training instabilities in previous models. We further highlight how data augmentation, multi-scale processing, and reservoir sampling can be used to improve model robustness and generation quality. Thirdly, we empirically evaluate stability of model architectures and show improved performance on a host of benchmarks and use cases, such as image generation, OOD detection, and compositional generation.
Improved Training of Energy-Based Models
Energy-Based Models (EBMs) represent the likelihood of a probability distribution of data by assigning an unnormalized probability scalar (or "energy") to each input data point. This provides significant model flexibility; any arbitrary model that outputs a real number can be used as an energy model. A difficulty however, is that training EBMs is hard, as to properly maximize the likelihood of an energy function, samples must be drawn from the energy model. In this work we present a set of improvements to contrastive divergence training of EBMs, enabling more stable, high resolution generation with EBMs. In particular we propose to:
- Add a KL loss term into contrastive divergence, which corresponds to a typically ignored gradient. We show that this significantly stabilizes and improves generative performance.
- Integrate data-augmentation transitions while training EBMs to encourage mode mixing between model samples.
- Factorize generation to a set of multi-scale energy functions operating on the input.
Contrastive Divergence
A common objective used to train EBMs is contrastive divergence. Contrastive divergence consists of the following objective: \[ \text{KL}(p_D(x) \ || \ p_{\theta} (x)) - \text{KL}(q_{\theta}(x) \ || \ p_{\theta}(x)). \] This objective minimizes the difference between the KL divergence of the data distribution and EBM distribution, and the KL divergence of finite number of MCMC steps on data distribution and EBM distribution. This objective has a key gradient (highlighted in red) that is often ignored. \[ - \left ( \mathbb{E}_{p_D(x)} \left [\frac{\partial E_{\theta}(x)}{\partial \theta} \right ] - \mathbb{E}_{q_{\theta}(x')} [\frac{\partial E_{\theta}(x')}{\partial \theta}] + {\color{red} \frac{\partial q(x')}{\partial \theta} \frac{\partial \text{KL}(q_{\theta}(x') \ || \ p_{\theta}(x'))}{\partial q_{\theta}(x')} } \right ) \] We present a KL loss to capture this gradient (see our paper for details). We find that this missing gradient contributes substantially to the overall training gradient of a EBM. The addition of our proposed KL loss significantly stablizes training of EBMs and enables us to add additional architectural blocks to training.
Data Augmentation
A difficulty when training EBMs is that underlying MCMC chains fail to mix and cover the EBM distribution. To enable more effective mixing of MCMC chains, we intersperse Langevin sampling with data augmentation transitions. This enables image sampling chains from our model to travel across large number of modes in the energy landscape. We illustrate the underlying sampling process below:
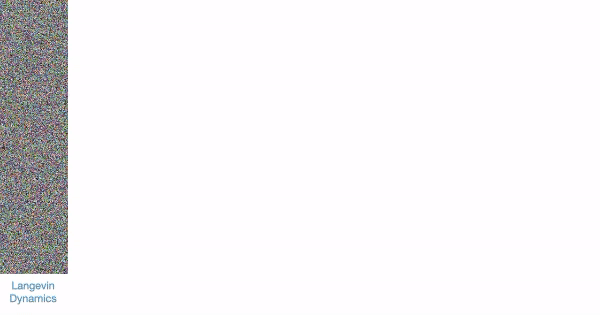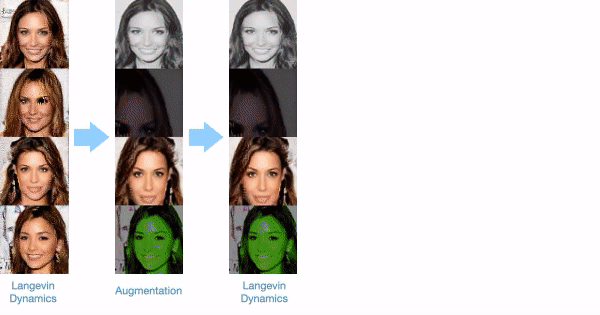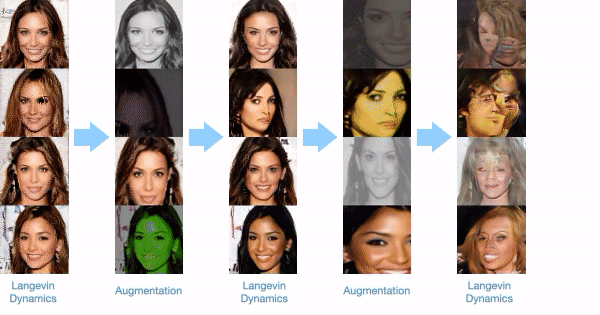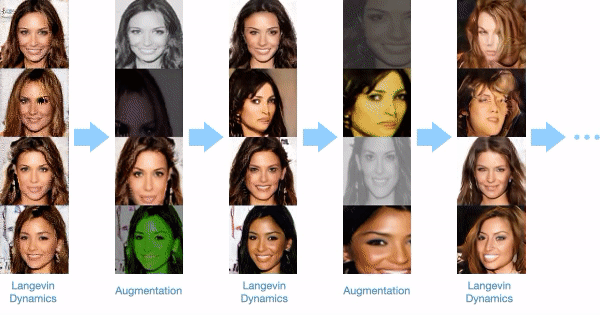
Zero Shot Compositional Generation
EBMs are able to independently compose with other EBMs, allowing us flexibly compose different models. We show that our approach enables higher resolution compositional generation across different domains. We independently train EBMs for CelebA factors of age, gender, smiling, and wavy hair. We show below that by adding each energy model in generation, we are able to gradually able to construct and change generations to exhibit each desired factor, as encoded by an individual energy function.
We can further independently train EBMs on rendering attributes of shape, size, position and rotation. By adding independent energy model in generation, we are also able to gradually construct generations that exhibit each desired factor.
Out of Distribution Robustness
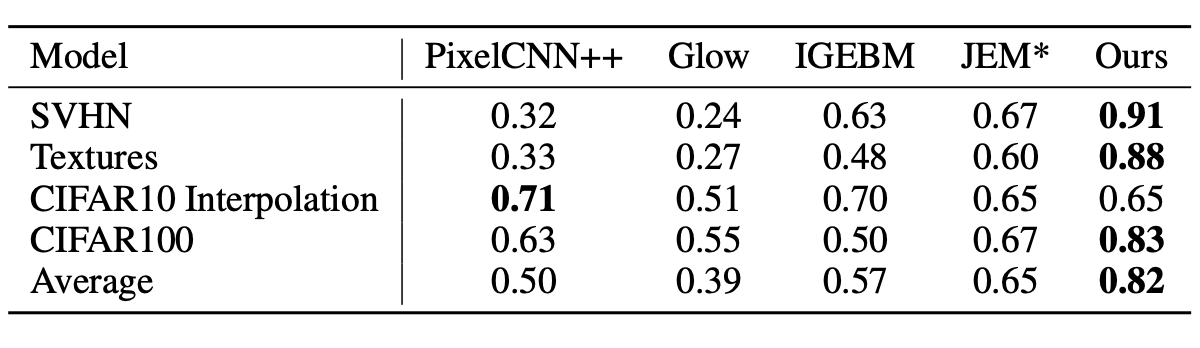
Another interesting property of EBMs is their ability to identify out-of-distribution samples not in the training data distribution by utilizing the output predicted energy. We find that our approach significantly outperforms other EBMs on the task of identifying out-of-distribution data samples.
Related Projects
Check out our related projects on utilizing energy based models!

Paper
