Nan Liu1*, Shuang Li2*,
Yilun Du2*, Antonio Torralba2,
Joshua B. Tenenbaum2
1UIUC, 2MIT
(* indicate equal contribution)
Compositional Generation using Stable Diffusion. Our proposed Conjunction (AND) and Negation (NOT) can be applied to conditional diffusion models for compositional generation. Our operators are added into Stable Diffusion WebUI! Corresponding pages are as follows: Conjunction (AND) and Negation (NOT).

"mystical trees" AND "A magical pond" AND "Dark"

"mystical trees" AND "A magical pond" AND NOT "Dark"
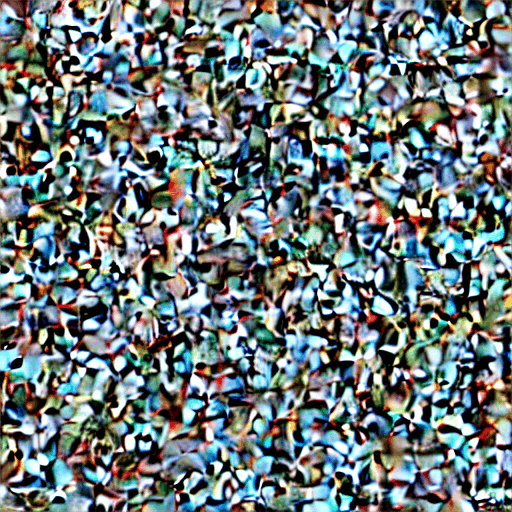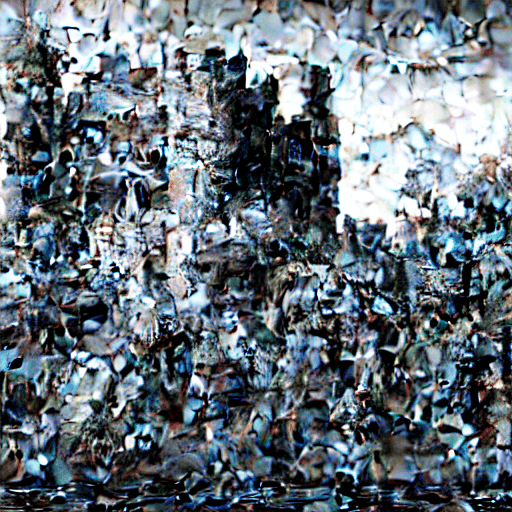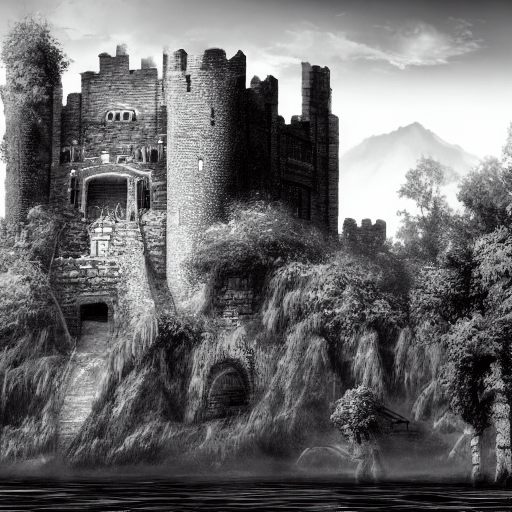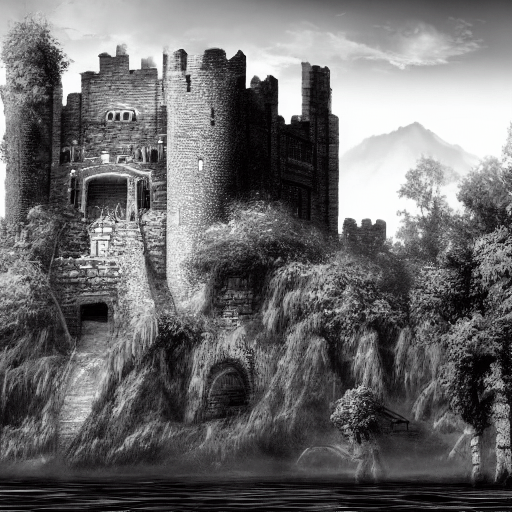
"A stone castle surrounded by lakes and trees, fantasy, wallpaper, concept art, extremely detailed" AND "Black and white"
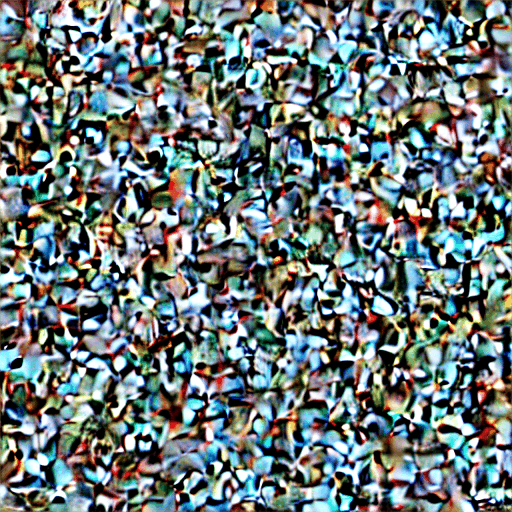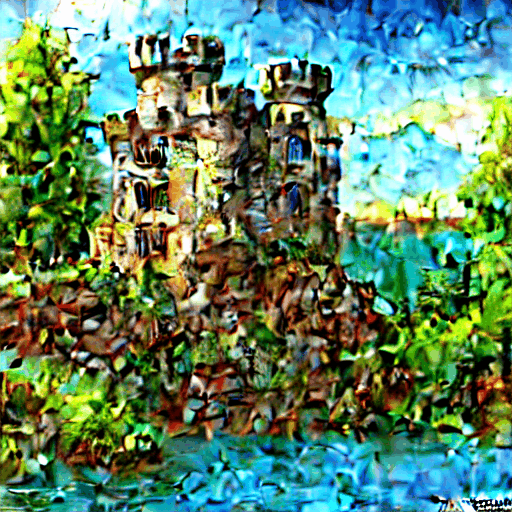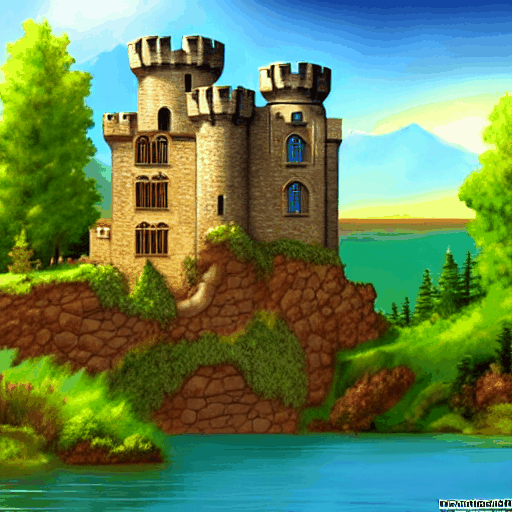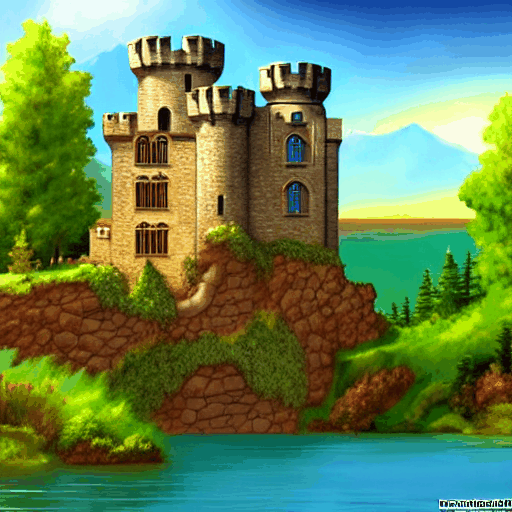
"A stone castle surrounded by lakes and trees, fantasy, wallpaper, concept art AND extremely detailed" AND NOT "Black and white"
Compositional 3D Generation using Point-E using our proposed Conjunction (AND) and and Negation (NOT) operators.

"A green avocado" AND "A chair"

"A chair" AND NOT "Chair legs"

"A toilet" AND "A chair"

"A couch" AND "A boat"

"A monitor" AND "A brown couch"

"A chair" AND "A cake"
Compose natural language descriptions:
Compose natural language descriptions:
Compose objects:
Compose object relational descriptions:


Compositional generation. Our method can compose multiple diffusion models during inference and generate images containing all the concepts described in the inputs without further training. We first send an image from iteration \(t\) and each individual concept \(c_i\) to the diffusion model to generate a set of scores \(\{\epsilon_\theta(\mathbf{x}_t, t|c_1), \ldots, \epsilon_\theta(\mathbf{x}_t, t|c_n)\}\). We then compose different concepts using the proposed compositional operators, such as conjunction, to denoise the generated images. The final image is obtained after \(T\) iterations.
Composing Language Descriptions. We develop Composed GLIDE (Ours), a version of GLIDE that utilizes our compositional operators to combine textual descriptions, without further training. We compare it to the original GLIDE, which directly encodes the descriptions as a single long sentence. Our approach more accurately captures text details, such as the "overwater bungalows" in the third example.

Composing Objects. Our method can compose multiple objects while baselines either miss or generate more objects.

Composing Visual Relations. Image generation results on the relational CLEVR dataset. Our model is trained to generate images conditioned on a single object relation, but during inference, our model can compose multiple object relations. The baseline methods either miss objects or generate more object relations.

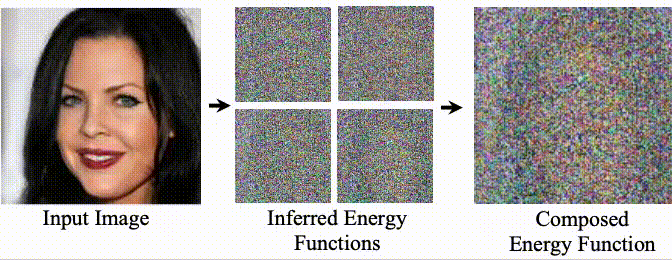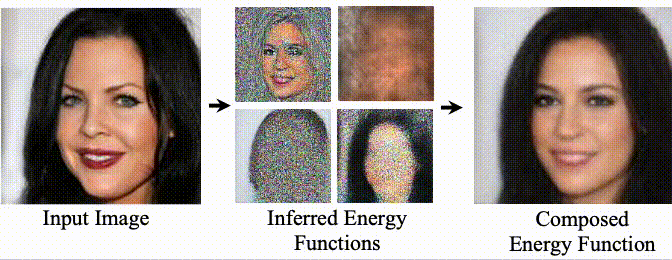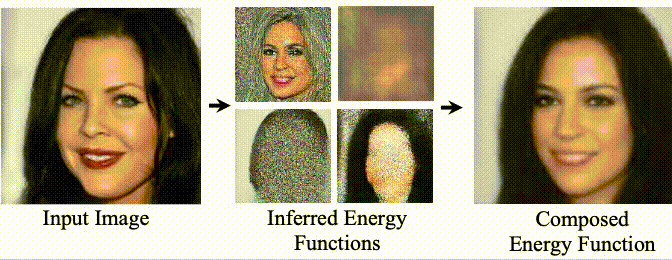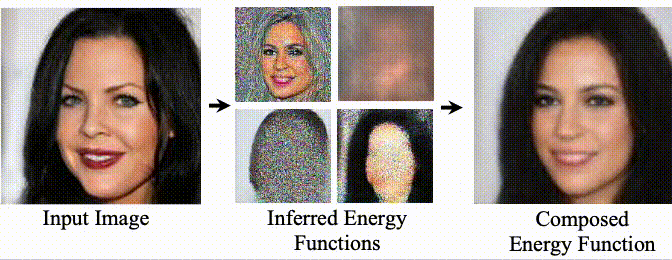
Composing Facial Attributes. Image generation results on the FFHQ dataset. Our model is trained to generate images conditioned on a single human facial attribute, but during inference, our model can recursively compose multiple facial attributes using the proposed compositional operators. The baselines either fail to compose attributes (StyleGAN2 and LACE) or generate low-quality images (EBM).

Success Examples. In each example, the first two images are generated conditioned on each individual sentence description and the last image is generated by composing the sentences.


Failure Examples. There are three main types of failures:
(1) The pre-trained diffusion model does not understand certain concepts, such as "person".
(2) The pre-trained duffision model confuses objects' attributes.
(3) The composition fails. This usually happens when the objects are in the center of the images.



Interesting Examples. Our method, which combines multiple textual descriptions, can generate different styles of images compared to GLIDE, which directly encodes the descriptions as a single long sentence. Prompted with 'a dog' and 'the sky', our method generates a dog-shaped cloud, whereas GLIDE generates a dog under the sky from the prompt 'a dog and the sky'.