Recent Publications
Runqian Wang, Yilun Du
arXiv Preprint
[Project] [Paper] [Code]
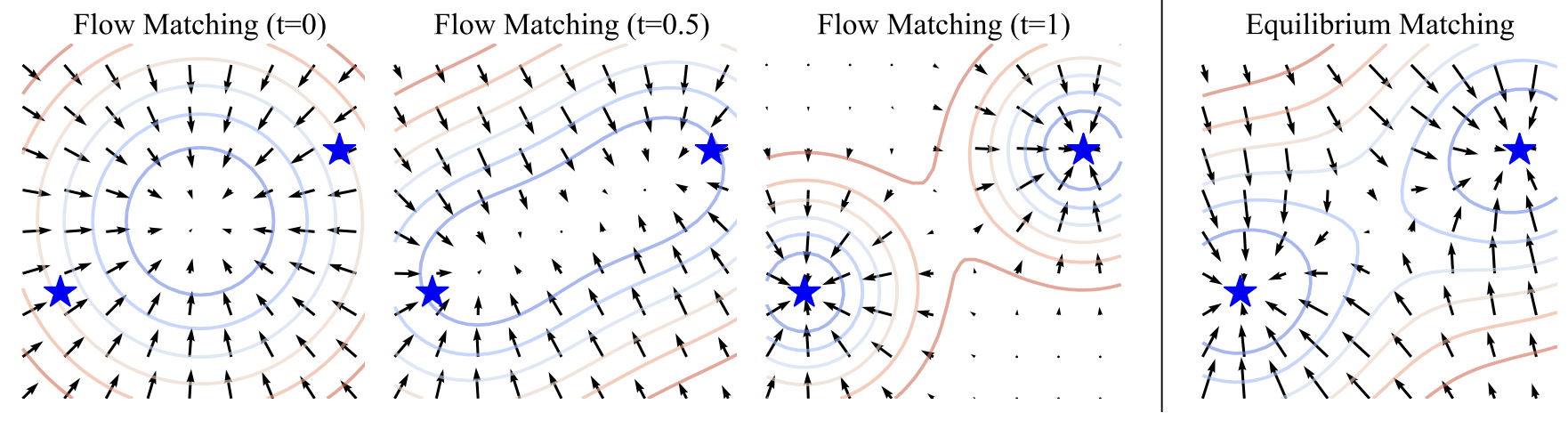
We introduce Equilibrium Matching (EqM), a generative modeling framework built from an equilibrium dynamics perspective. EqM discards the non-equilibrium, time-conditional dynamics in traditional diffusion and flow-based generative models and instead learns the equilibrium gradient of an implicit energy landscape. Through this approach, we can adopt an optimization-based sampling process at inference time, where samples are obtained by gradient descent on the learned landscape with adjustable step sizes, adaptive optimizers, and adaptive compute. EqM surpasses the generation performance of diffusion/flow models empirically, achieving an FID of 1.90 on ImageNet 256×256. EqM is also theoretically justified to learn and sample from the data manifold. Beyond generation, EqM is a flexible framework that naturally handles tasks including partially noised image denoising, OOD detection, and image composition. By replacing time-conditional velocities with a unified equilibrium landscape, EqM offers a tighter bridge between flow and energy-based models and a simple route to optimization-driven inference.
Alexandru Oarga, Yilun Du
NeurIPS 2025
[Project] [Paper] [Code]
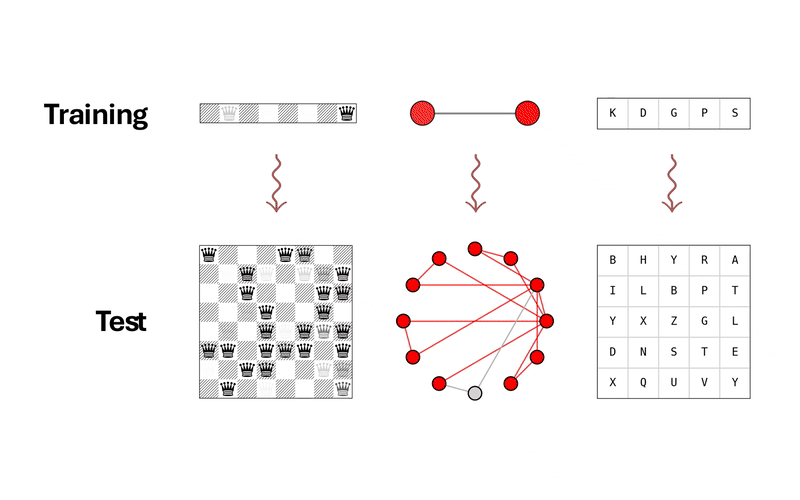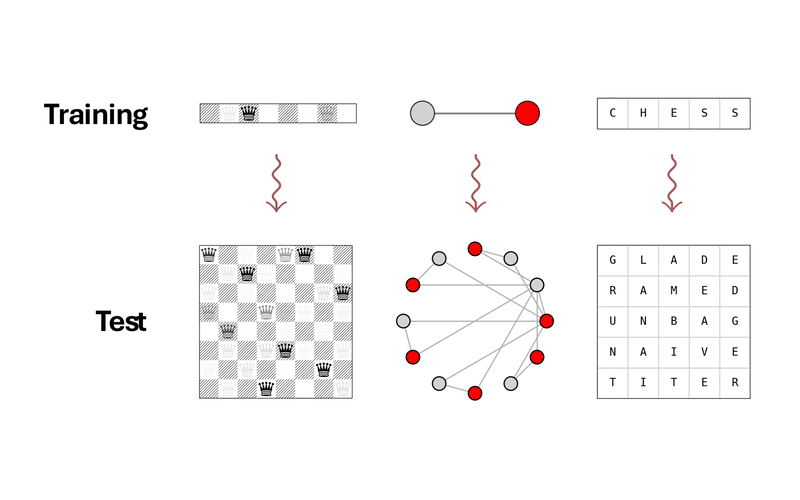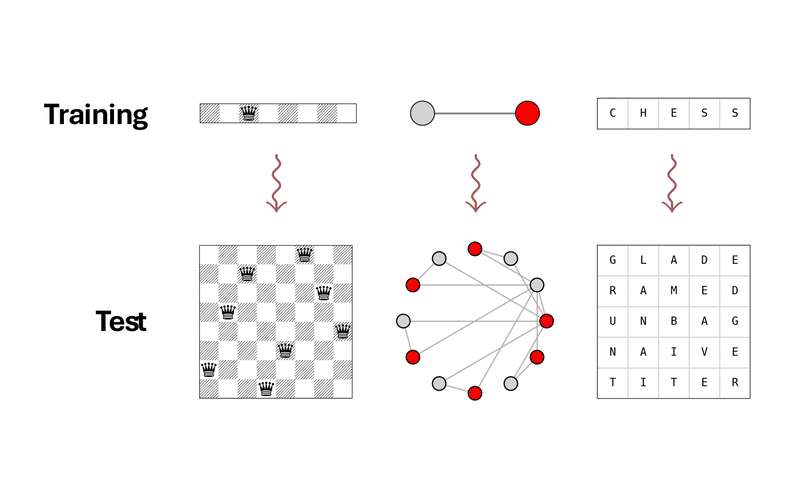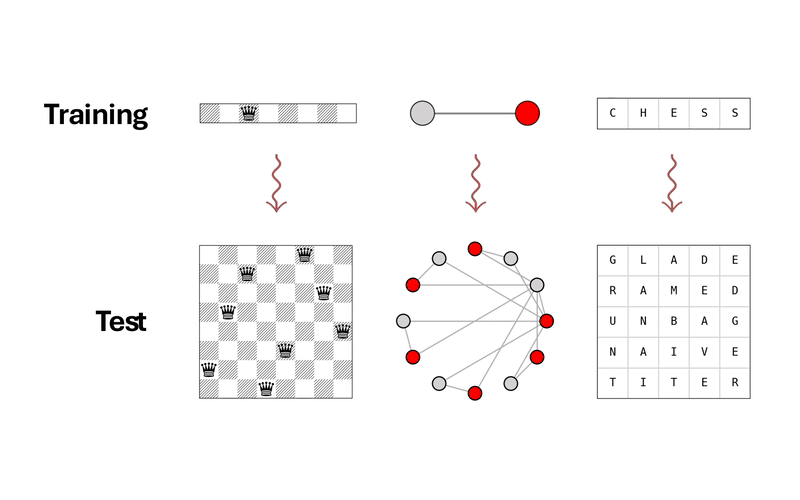
Generalization is a key challenge in machine learning, specifically in reasoning tasks, where models are expected to solve problems more complex than those encountered during training. Existing approaches typically train reasoning models in an end-to-end fashion, directly mapping input instances to solutions. While this allows models to learn useful heuristics from data, it often results in limited generalization beyond the training distribution. In this work, we propose a novel approach to reasoning generalization by learning energy landscapes over the solution spaces of smaller, more tractable subproblems. At test time, we construct a global energy landscape for a given problem by combining the energy functions of multiple subproblems. This compositional approach enables the incorporation of additional constraints during inference, allowing the construction of energy landscapes for problems of increasing difficulty. To improve the sample quality from this newly constructed energy landscape, we introduce Parallel Energy Minimization (PEM). We evaluate our approach on a wide set of reasoning problems. Our method outperforms existing state-of-the-art methods, demonstrating its ability to generalize to larger and more complex problems.
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, Tariq Iqbal
arXiv Preprint
[Project] [Paper] [Blog] [Code]
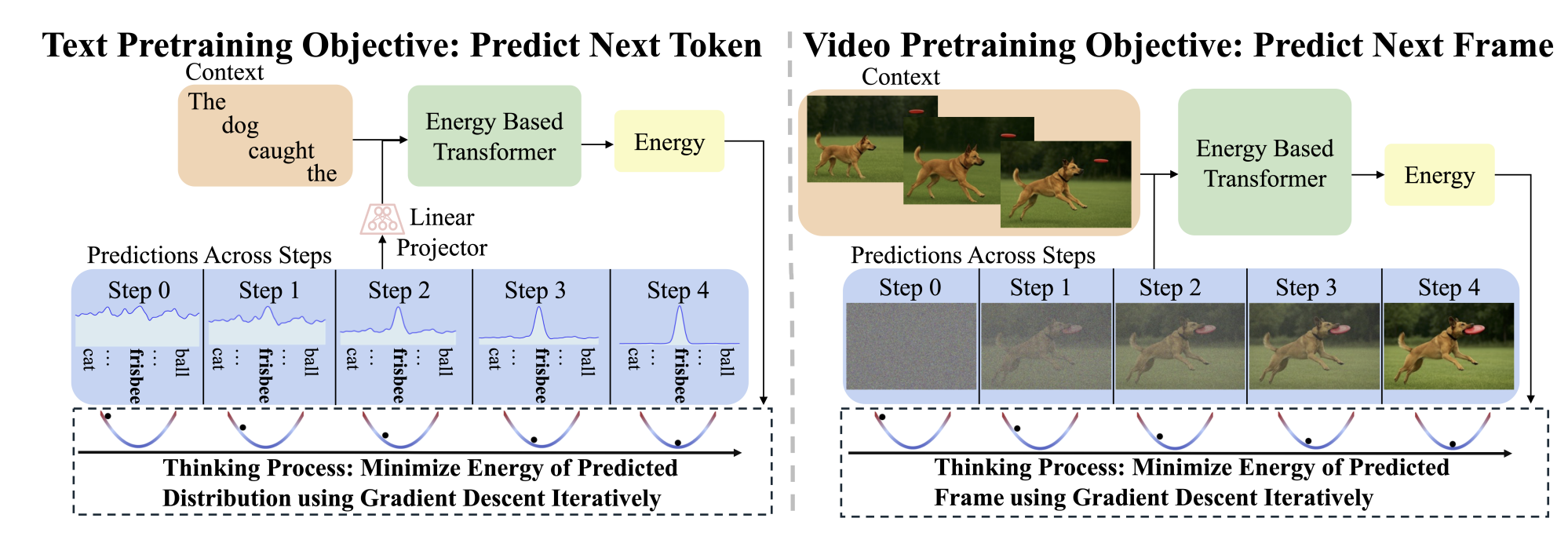
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question “Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?” Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs)—a new class of Energy-Based Models (EBMs)—to assign an energy (unnormalized probability) value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. This formulation enables System 2 Thinking to emerge from unsupervised learning, making it modality and problem agnostic. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking (i.e., extra computation) by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that System 2 Thinking with EBTs yields larger performance improvements on data that is farther out-of-distribution, and that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.

Yanbo Wang, Justin Dauwels, Yilun Du
ICML 2025
[Project] [Paper] [Code]
We explore how generative models can be used not only to synthesize visual content but also to understand the properties of a scene given a natural image. We formulate scene understanding as an inverse generative modeling problem, where we seek to find conditional parameters of a visual generative model to best fit a given natural image. To enable this procedure to infer scene structure from images substantially different than those seen during training, we further propose to build this visual generative model compositionally from smaller models over pieces of a scene. We illustrate how this procedure enables us to infer the set of objects in a scene, enabling robust generalization to new test scenes with an increased number of objects of new shapes. We further illustrate how this enables us to infer global scene factors, likewise enabling robust generalization to new scenes. Finally, we illustrate how this approach can be directly applied to existing pretrained text-to-image generative models for zero-shot multi-object perception.
Yilun Du*, Jiayuan Mao*, Joshua Tenenbaum
ICML 2024
[Project] [Paper] [Code]
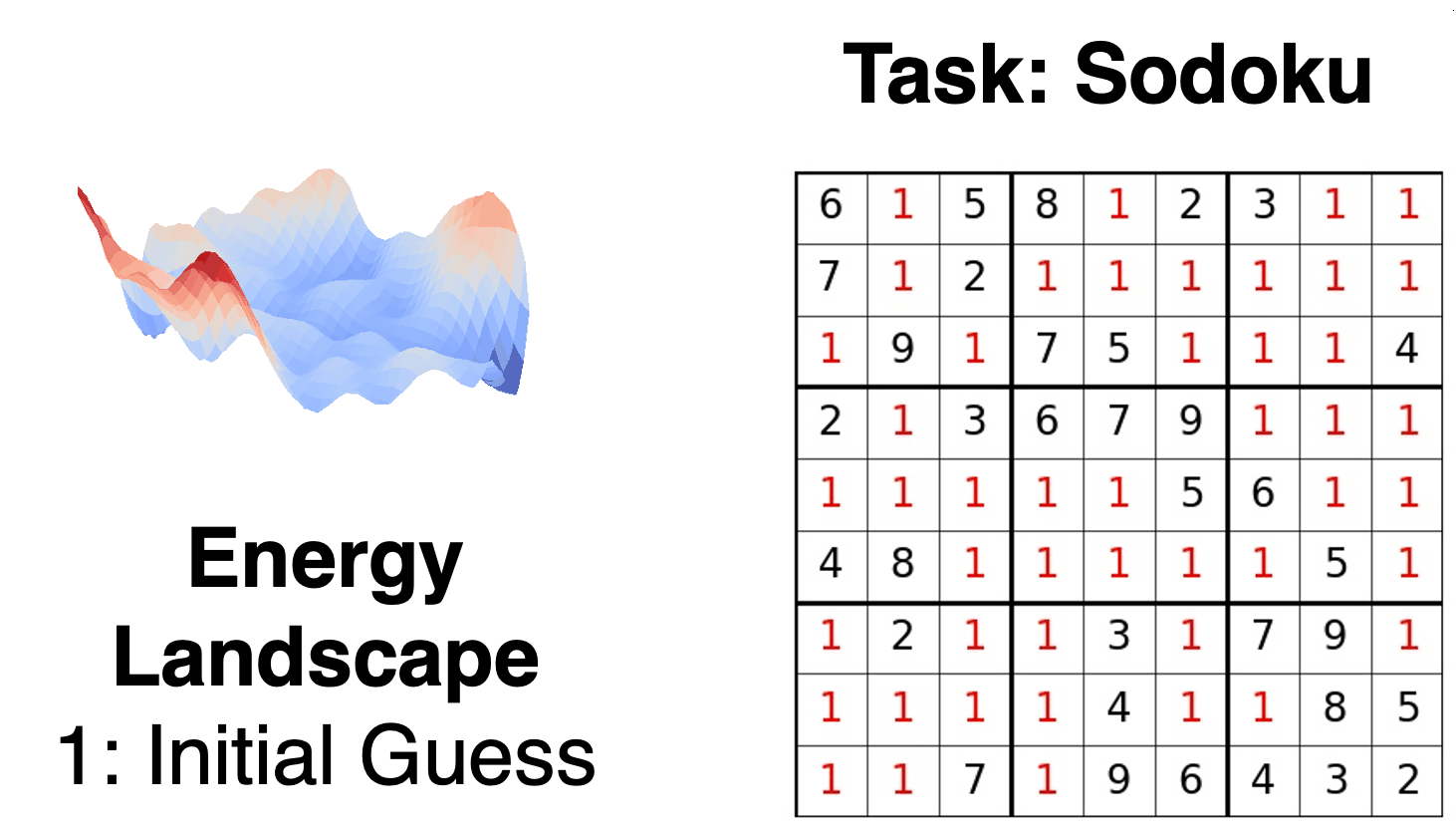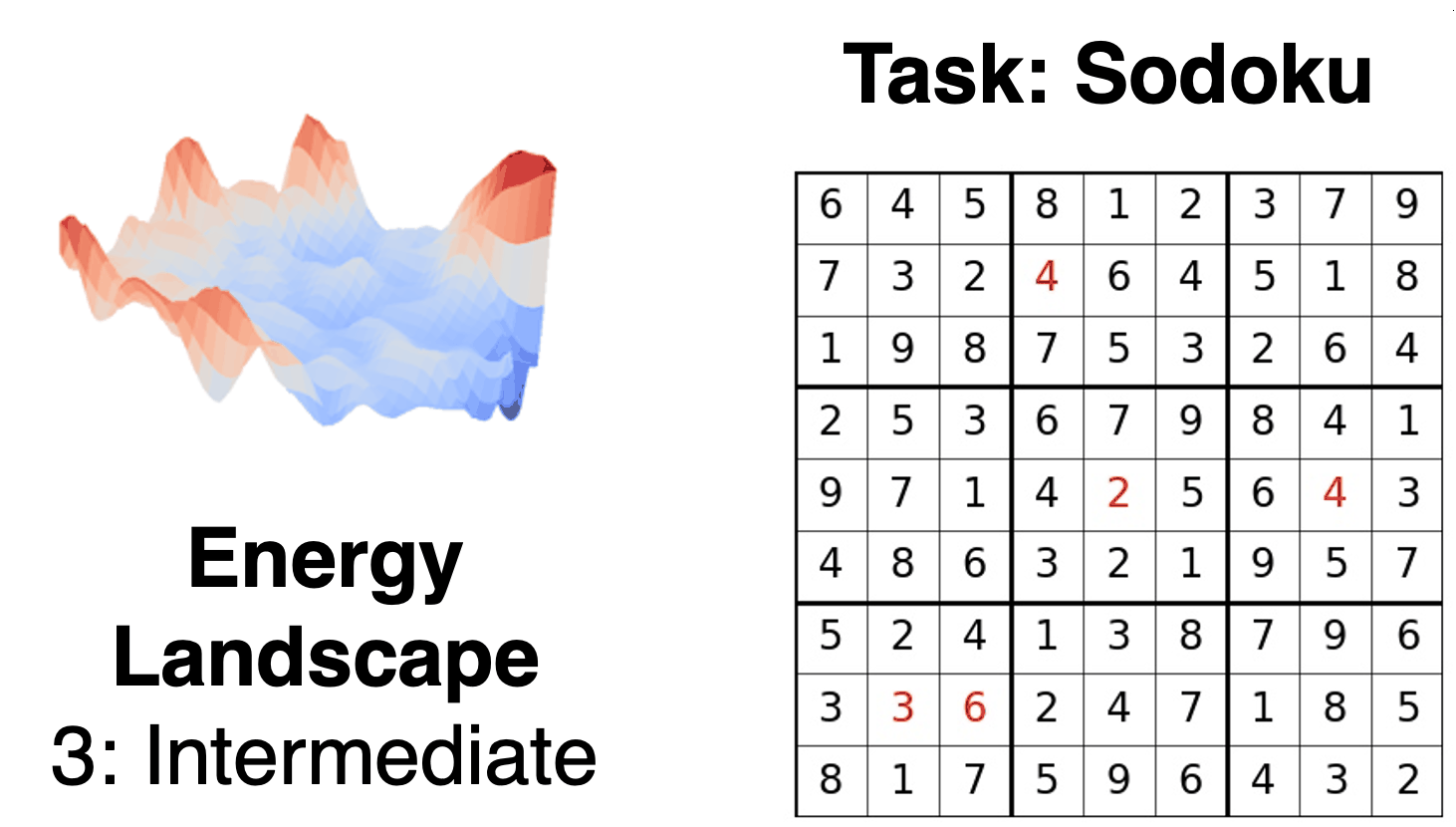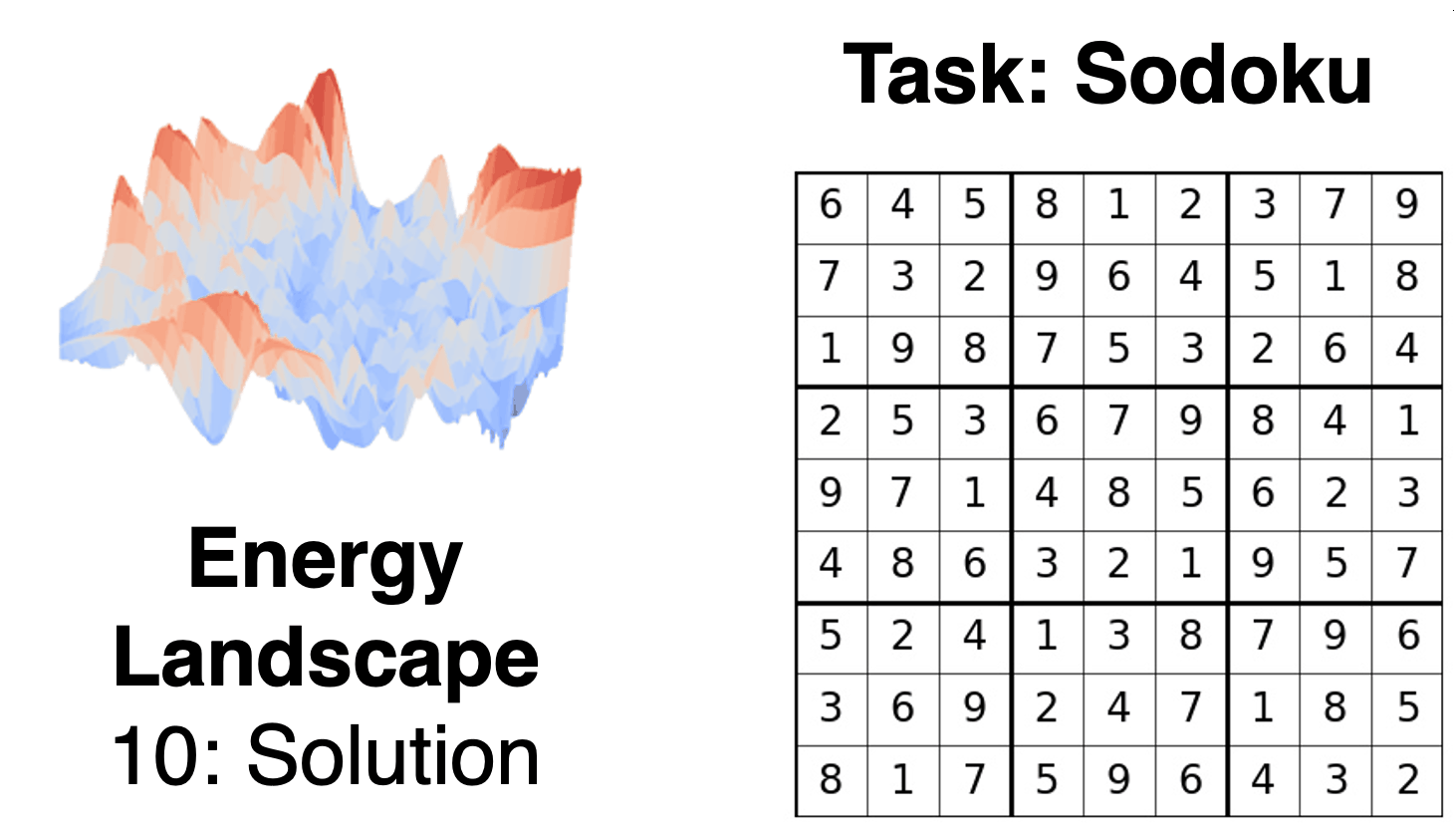
We introduce iterative reasoning through energy diffusion (IRED), a novel framework for learning to reason for a variety of tasks by formulating reasoning and decision-making problems with energy-based optimization. IRED learns energy functions to represent the constraints between input conditions and desired outputs. After training, IRED adapts the number of optimization steps during inference based on problem difficulty, enabling it to solve problems outside its training distribution -- such as more complex Sudoku puzzles, matrix completion with large value magnitudes, and pathfinding in larger graphs. Key to our method's success is two novel techniques: learning a sequence of annealed energy landscapes for easier inference and a combination of score function and energy landscape supervision for faster and more stable training. Our experiments show that IRED outperforms existing methods in continuous-space reasoning, discrete-space reasoning, and planning tasks, particularly in more challenging scenarios.

Jocelin Su*, Nan Liu*, Yanbo Wang*, Joshua B. Tenenbaum, Yilun Du
ICML 2024
[Project] [Paper] [Code]
Given an image of a natural scene, we are able to quickly decompose it into a set of components such as objects, lighting, shadows, and foreground. We can then envision a scene where we combine certain components with those from other images, for instance a set of objects from our bedroom and animals from a zoo under the lighting conditions of a forest, even if we have never encountered such a scene before. In this paper, we present a method to decompose an image into such compositional components. Our approach, Decomp Diffusion, is an unsupervised method which, when given a single image, infers a set of different components in the image, each represented by a diffusion model. We demonstrate how components can capture different factors of the scene, ranging from global scene descriptors like shadows or facial expression to local scene descriptors like constituent objects. We further illustrate how inferred factors can be flexibly composed, even with factors inferred from other models, to generate a variety of scenes sharply different than those seen in training time.
Yunhao Luo, Chen Sun, Joshua B. Tenenbaum, Yilun Du
ICML 2024
[Project] [Paper] [Code] [Colab]
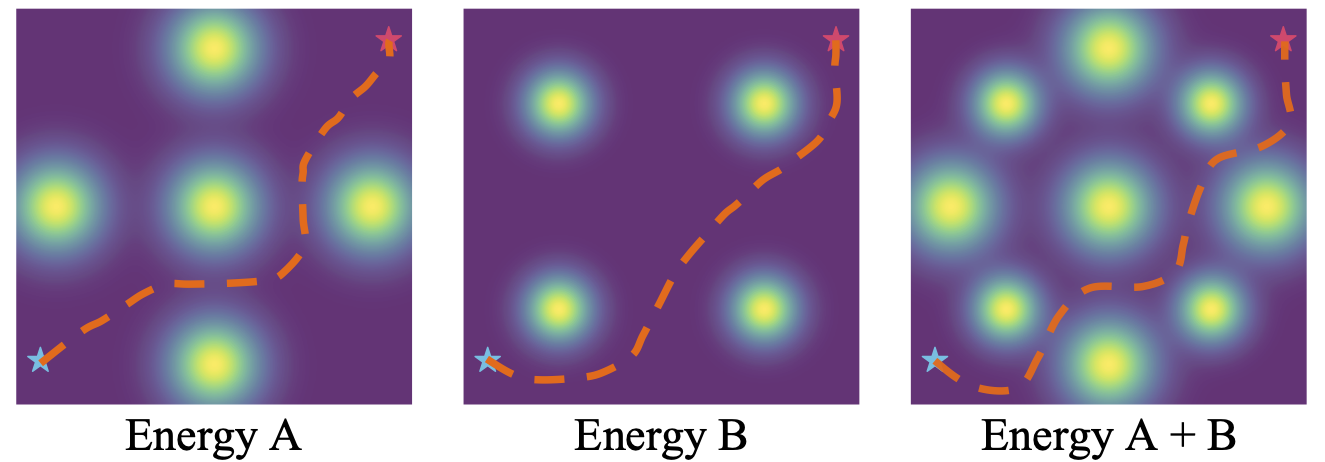
Effective motion planning in high dimensional spaces is a long-standing open problem in robotics. One class of traditional motion planning algorithms corresponds to potential-based motion planning. An advantage of potential based motion planning is composability– different motion constraints can be easily combined by adding corresponding potentials. However, constructing motion paths from potentials requires solving a global optimization across configuration space potential landscape, which is often prone to local minima. We propose a new approach towards learning potential based motion planning, where we train a neural network to capture and learn an easily optimizable potentials over motion planning trajectories. We illustrate the effectiveness of such approach, significantly outperforming both classical and recent learned motion planning approaches and avoiding issues with local minima. We further illustrate its inherent composability, enabling us to generalize to a multitude of different motion constraints.
Yilun Du, Leslie Kaelbling
ICML 2024
[Paper]
Large monolithic generative models trained on massive amounts of data have become an increasingly dominant approach in AI research. In this paper, we argue that we should instead construct large generative systems by composing smaller generative models together. We show how such a compositional generative approach enables us to learn distributions in a more data-efficient manner, enabling generalization to parts of the data distribution unseen at training time. We further show how this enables us to program and construct new generative models for tasks completely unseen at training. Finally, we show that in many cases, we can discover separate compositional components from data.
Nan Liu*, Yilun Du*, Shuang Li*, Joshua B. Tenenbaum, Antonio Torralba
ICCV 2023
[Project] [Paper] [Code]
Text-to-image generative models have enabled high-resolution image synthesis across different domains, but require users to specify the content they wish to generate. In this paper, we consider the inverse problem -- given a collection of different images, can we discover the generative concepts that represent each image? We present an unsupervised approach to discover generative concepts from a collection of images, disentangling different art styles in paintings, objects, and lighting from kitchen scenes, and discovering image classes given ImageNet images. We show how such generative concepts can accurately represent the content of images, be recombined and composed to generate new artistic and hybrid images, and be further used as a representation for downstream classification tasks.
Armand Comas, Yilun Du, Christian Fernandez Lopez, Sandesh Ghimire, Mario Sznaier, Joshua B. Tenenbaum, Octavia Camps
ICML 2023, Oral
[Project] [Paper] [Code]
Systems consisting of interacting agents are prevalent in the world, ranging from dynamical systems in physics to complex biological networks. To build systems which can interact robustly in the real world, it is thus important to be able to infer the precise interactions governing such systems. Existing approaches typically discover such interactions by explicitly modeling the feed-forward dynamics of the trajectories. In this work, we propose Neural Interaction Inference with Potentials (NIIP) as an alternative approach to discover such interactions that enables greater flexibility in trajectory modeling: it discovers a set of relational potentials, represented as energy functions, which when minimized reconstruct the original trajectory. NIIP assigns low energy to the subset of trajectories which respect the relational constraints observed. We illustrate that with these representations NIIP displays unique capabilities in test-time. First, it allows trajectory manipulation, such as interchanging interaction types across separately trained models, as well as trajectory forecasting. Additionally, it allows adding external hand-crafted potentials at test-time. Finally, NIIP enables the detection of out-of-distribution samples and anomalies without explicit training.
Yilun Du, Conor Durkan, Robin Strudel, Joshua B. Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, Will Grathwohl
ICML 2023
[Project] [Paper] [Colab] [Code]
Since their introduction, diffusion models have quickly become the prevailing approach to generative modeling in many domains. They can be interpreted as learning the gradients of a time-varying sequence of log-probability density functions. This interpretation has motivated classifier-based and classifier-free guidance as methods for post-hoc control of diffusion models. In this work, we build upon these ideas using the score-based interpretation of diffusion models, and explore alternative ways to condition, modify, and reuse diffusion models for tasks involving compositional generation and guidance. In particular, we investigate why certain types of composition fail using current techniques and present a number of solutions. We conclude that the sampler (not the model) is responsible for this failure and propose new samplers, inspired by MCMC, which enable successful compositional generation. Further, we propose an energy-based parameterization of diffusion models which enables the use of new compositional operators and more sophisticated, Metropolis-corrected samplers. Intriguingly we find these samplers lead to notable improvements in compositional generation across a wide set of problems such as classifier-guided ImageNet modeling and compositional text-to-image generation.
Shuang Li*, Yilun Du*, Joshua B. Tenenbaum, Antonio Torralba, Igor Mordatch
(*equal contribution. Shuang Li did experiments on image generation, video question answering, and mathematical reasoning. Yilun Du did all the experiments on robot manipulation.)
ICLR 2023
[Project] [Paper]
Large pre-trained models exhibit distinct and complementary capabilities dependent on the data they are trained on. Language models such as GPT-3 are capable of textual reasoning but cannot understand visual information, while vision models such as DALL-E can generate photorealistic photos but fail to understand complex language descriptions. In this work, we propose a unified framework for composing ensembles of different pre-trained models -- combining the strengths of each individual model to solve various multimodal problems in a zero-shot manner. We use pre-trained models as "generators" or "scorers" and compose them via closed-loop iterative consensus optimization. The generator constructs proposals and the scorers iteratively provide feedback to refine the generated result. Such closed-loop communication enables models to correct errors caused by other models, significantly boosting performance on downstream tasks, e.g. improving accuracy on grade school math problems by 7.5%, without requiring any model finetuning. We demonstrate that consensus achieved by an ensemble of scorers outperforms the feedback of a single scorer, by leveraging the strengths of each expert model. Results show that the proposed method can be used as a general purpose framework for a wide range of zero-shot multimodal tasks, such as image generation, video question answering, mathematical reasoning, and robotic manipulation.
Nan Liu*, Shuang Li*, Yilun Du*, Antonio Torralba Joshua B. Tenenbaum, and (*equal contribution)
ECCV 2022
[Project] [Paper] [Code] [Colab] [HuggingFace Demo]
Press coverage: MIT News, MIT CSAIL News
Large text-guided diffusion models, such as DALLE-2, are able to generate stunning photorealistic images given natural language descriptions. While such models are highly flexible, they struggle to understand the composition of certain concepts, such as confusing the attributes of different objects or relations between objects. In this paper, we propose an alternative structured approach for compositional generation using diffusion models. An image is generated by composing a set of diffusion models, with each of them modeling a certain component of the image. To do this, we interpret diffusion models as energy-based models in which the data distributions defined by the energy functions may be explicitly combined. The proposed method can generate scenes at test time that are substantially more complex than those seen in training, composing sentence descriptions, object relations, human facial attributes, and even generalizing to new combinations that are rarely seen in the real world. We further illustrate how our approach may be used to compose pre-trained text-guided diffusion models and generate photorealistic images containing all the details described in the input descriptions, including the binding of certain object attributes that have been shown difficult for DALLE-2. These results point to the effectiveness of the proposed method in promoting structured generalization for visual generation.
Yilun Du, Shuang Li, Joshua B. Tenenbaum, and Igor Mordatch
ICML 2022
[Project] [Paper] [Code]
Deep learning has excelled on complex pattern recognition tasks such as image classification and object recognition. However, it struggles with tasks requiring nontrivial reasoning, such as algorithmic computation. Humans are able to solve such tasks through iterative reasoning -- spending more time thinking about harder tasks. Most existing neural networks, however, exhibit a fixed computational budget controlled by the neural network architecture, preventing additional computational processing on harder tasks. In this work, we present a new framework for iterative reasoning with neural networks. We train a neural network to parameterize an energy landscape over all outputs, and implement each step of the iterative reasoning as an energy minimization step to find a minimal energy solution. By formulating reasoning as an energy minimization problem, for harder problems that lead to more complex energy landscapes, we may then adjust our underlying computational budget by running a more complex optimization procedure. We empirically illustrate that our iterative reasoning approach can solve more accurate and generalizable algorithmic reasoning tasks in both graph and continuous domains. Finally, we illustrate that our approach can recursively solve algorithmic problems requiring nested reasoning.
Yilun Du, Shuang Li, Yash Sharma, Joshua B. Tenenbaum, and Igor Mordatch
NeurIPS 2021
[Project] [Paper] [Code]
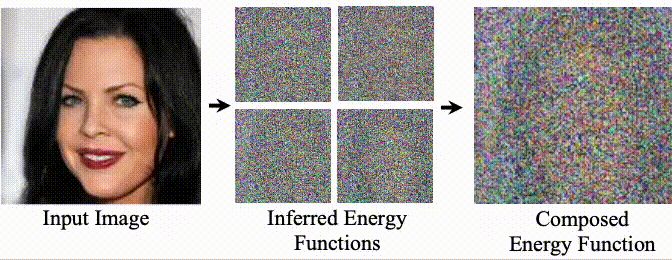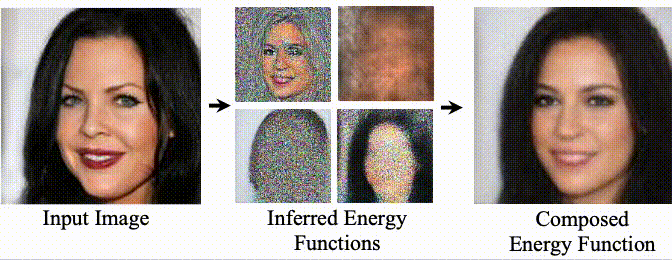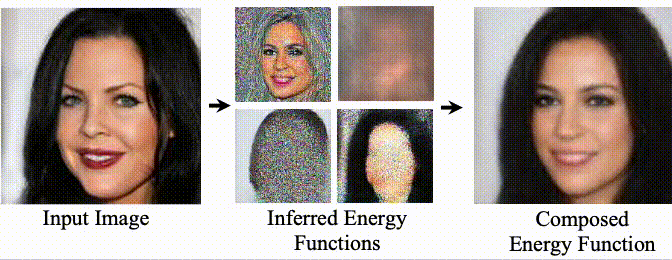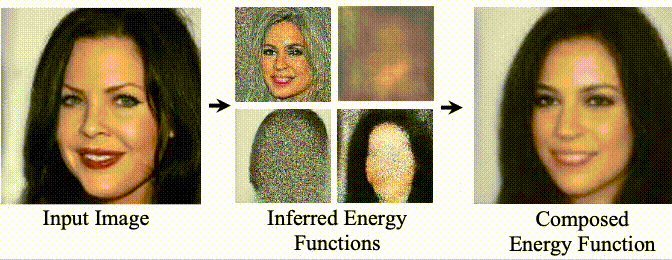
We introduce an approach to decompose images, in an unsupervised manner, into separate component energy functions. These energy functions can both represent global factors of variation, such as facial expression and hair color, as well as local factors of variations, such as the objects in a scene. Decomposed energy functions generalize well, and may be recombined with energy function discovered by training a separate instance of approach on a different dataset, enabling the recombination of objects and lighting conditions across datasets.
Nan Liu*, Shuang Li*, Yilun Du*, Joshua B. Tenenbaum, and Antonio Torralba (*equal contribution)
NeurIPS 2021, Spotlight
NeurIPS Workshop on Controllable Generative Modeling 2021, Outstanding Paper Award
Press coverage: MIT News, MIT CSAIL News
[Project] [Paper] [Code]
The visual world around us can be described as a structured set of objects and their associated relations. In this work, we propose to represent each relation as an unnormalized density (an energy-based model), enabling us to compose separate relations in a factorized manner. We show that such a factorized decomposition allows the model to both generate and edit scenes that have multiple sets of relations more faithfully. We further show that decomposition enables our model to effectively understand the underlying relational scene structure.
Yilun Du, Shuang Li, Joshua B. Tenenbaum, and Igor Mordatch
ICML 2021
ICLR EBM Workshop 2021, Oral
[Project] [Paper] [Code]
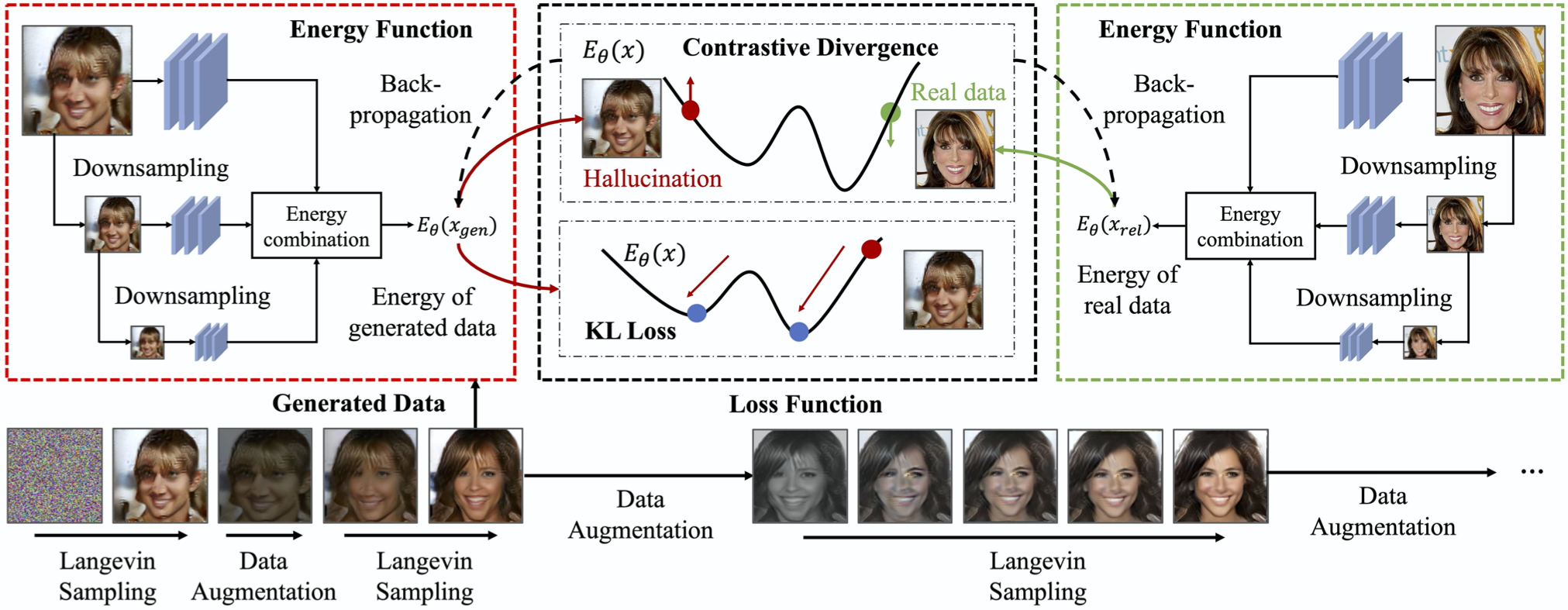
We present tools to improve the underlying contrastive divergence objective for training EBMs. First we illustrate a neglected term in contrastive divergence training of EBMs, and present a loss function to mitigate this term. We further propose to utilize data augmentation to aid the mixing of MCMC chains when training EBMs and propose to use a multiscale architecture to further improve the underlying generative performance. We illustrate how our tricks improve the underlying generative performance of EBMs, and further show improved out-of-distribution detection.
Shuang Li, Yilun Du, Gido M. van de Ven, and Igor Mordatch
CoLLAs 2022, Oral
ICLR EBM Workshop 2021, Oral
[Project] [Paper] [Code]
We motivate Energy-Based Models (EBMs) as a promising model class for continual learning problems. Instead of tackling continual learning via the use of external memory, growing models, or regularization, EBMs change the underlying training objective to causes less interference with previously learned information. Our proposed version of EBMs for continual learning is simple, efficient, and outperforms baseline methods by a large margin on several benchmarks. Moreover, our proposed contrastive divergence based training objective can be applied to other continual learning methods, resulting in substantial boosts in their performance.

Yilun Du, Shuang Li, and Igor Mordatch
NeurIPS 2020, Spotlight
[Project] [Paper] [Code]
A vital aspect of human intelligence is the ability to compose increasingly complex concepts out of simpler ideas, enabling both rapid learning and adaptation of knowledge. In this paper we show that energy-based models can exhibit this ability by directly combining probability distributions. Samples from the combined distribution correspond to compositions of concepts. For example, given one distribution for smiling face images, and another for male faces, we can combine them to generate smiling male faces. This allows us to generate natural images that simultaneously satisfy conjunctions, disjunctions, and negations of concepts. We evaluate compositional generation abilities of our model on the CelebA dataset of natural faces and synthetic 3D scene images. We showcase the breadth of unique capabilities of our model, such as the ability to continually learn and incorporate new concepts, or infer compositions of concept properties underlying an image.
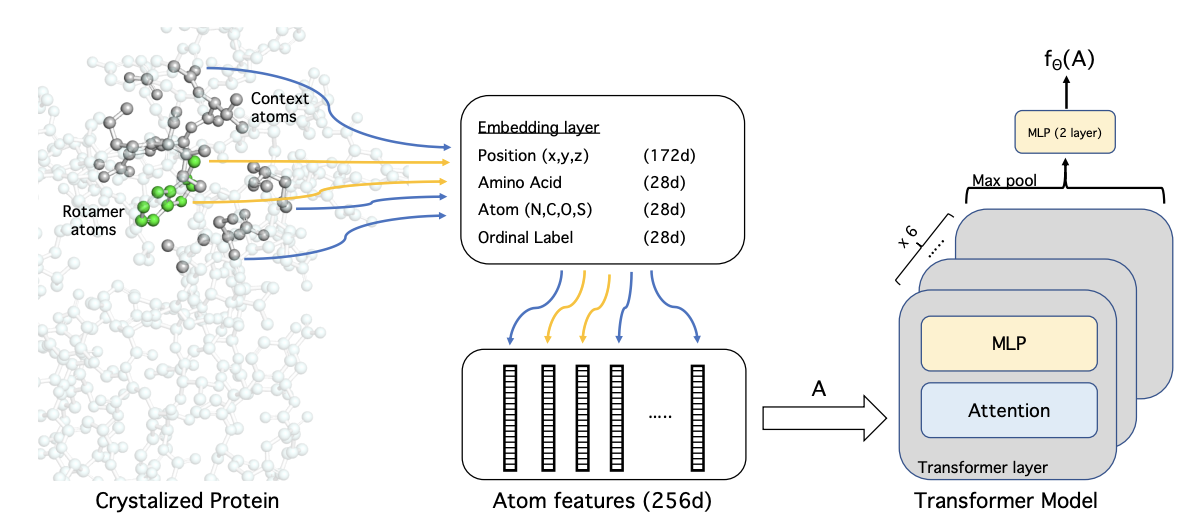
Yilun Du, Joshua Meier, Jerry Ma, Rob Fergus, and Alexander Rives
ICLR 2020, Spotlight
[Paper] [Code]
We propose an energy-based model (EBM) of protein conformations that operates at atomic scale. The model is trained solely on crystallized protein data. By contrast, existing approaches for scoring conformations use energy functions that incorporate knowledge of physical principles and features that are the complex product of several decades of research and tuning. To evaluate the model, we benchmark on the rotamer recovery task, the problem of predicting the conformation of a side chain from its context within a protein structure, which has been used to evaluate energy functions for protein design. The model achieves performance close to that of the Rosetta energy function, a state-of-the-art method widely used in protein structure prediction and design. An investigation of the model’s outputs and hidden representations finds that it captures physicochemical properties relevant to protein energy.
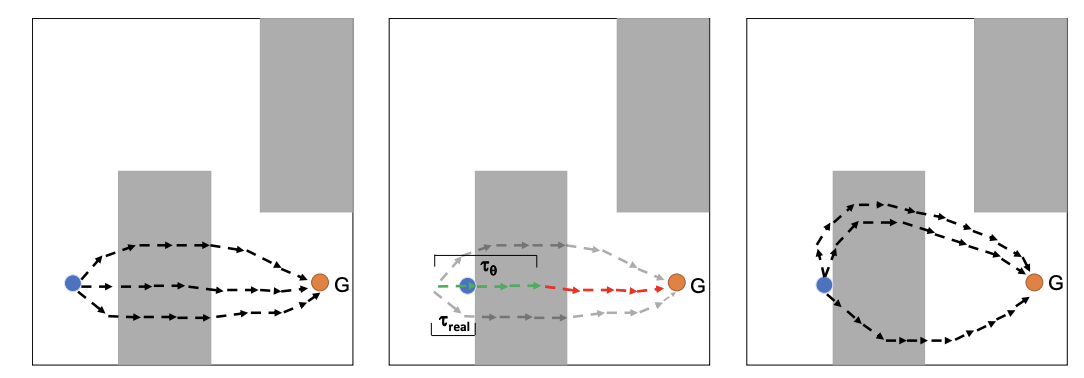
Yilun Du, Toru Lin, and Igor Mordatch
CORL 2019
ICML MBRL Workshop 2019, Oral
[Paper] [Code]
Model-based planning holds great promise for improving both sample efficiency and generalization in reinforcement learning (RL). We show that energy-based models (EBMs) are a promising class of models to use for model-based planning. EBMs naturally support inference of intermediate states given start and goal state distributions. We provide an online algorithm to train EBMs while interacting with the environment, and show that EBMs allow for significantly better online learning than corresponding feed-forward networks. We further show that EBMs support maximum entropy state inference and are able to generate diverse state space plans. We show that inference purely in state space - without planning actions - allows for better generalization to previously unseen obstacles in the environment and prevents the planner from exploiting the dynamics model by applying uncharacteristic action sequences.
Yilun Du and Igor Mordatch
NeurIPS 2019, Spotlight
[OpenAI Blog] [Paper] [Code]
Energy Based Models (EBMs) are a appealing class of models due to their generality and simplicity in likelihood modeling. However, EBMs have been traditionally hard to train. We present techniques to scale MCMC based training of EBMs on continuous neural networks on high-dimensional data domains such as ImageNet128x128 and robotic hand trajectories. We highlight some unique capabilities of implicit generation. Finally, we illustrate how EBMs are a useful class of models across a wide variety of tasks, achieving out-of-distribution generalization, adversarially robust classification, online continual learning, and compositionality.