Composing Ensembles of Pre-trained Models via Iterative Consensus
Abstract
Large pre-trained models exhibit distinct and complementary capabilities dependent on the data they are trained on. Language models such as GPT-3 are capable of textual reasoning but cannot understand visual information, while vision models such as DALL-E can generate photorealistic photos but fail to understand complex language descriptions.
In this work, we propose a unified framework for composing ensembles of different pre-trained models -- combining the strengths of each individual model to solve various multimodal problems in a zero-shot manner. We use pre-trained models as "generators" or "scorers" and compose them via closed-loop iterative consensus optimization. The generator constructs proposals and the scorers iteratively provide feedback to refine the generated result. Such closed-loop communication enables models to correct errors caused by other models, significantly boosting performance on downstream tasks, e.g. improving accuracy on grade school math problems by 7.5%, without requiring any model finetuning. We demonstrate that consensus achieved by an ensemble of scorers outperforms the feedback of a single scorer, by leveraging the strengths of each expert model. Results show that the proposed method can be used as a general purpose framework for a wide range of zero-shot multimodal tasks, such as image generation, video question answering, mathematical reasoning, and robotic manipulation.
Method
The proposed framework that composes a "generator" and an ensemble of "scorers" through iterative consensus enables zero-shot generalization across a variety of multimodal tasks.
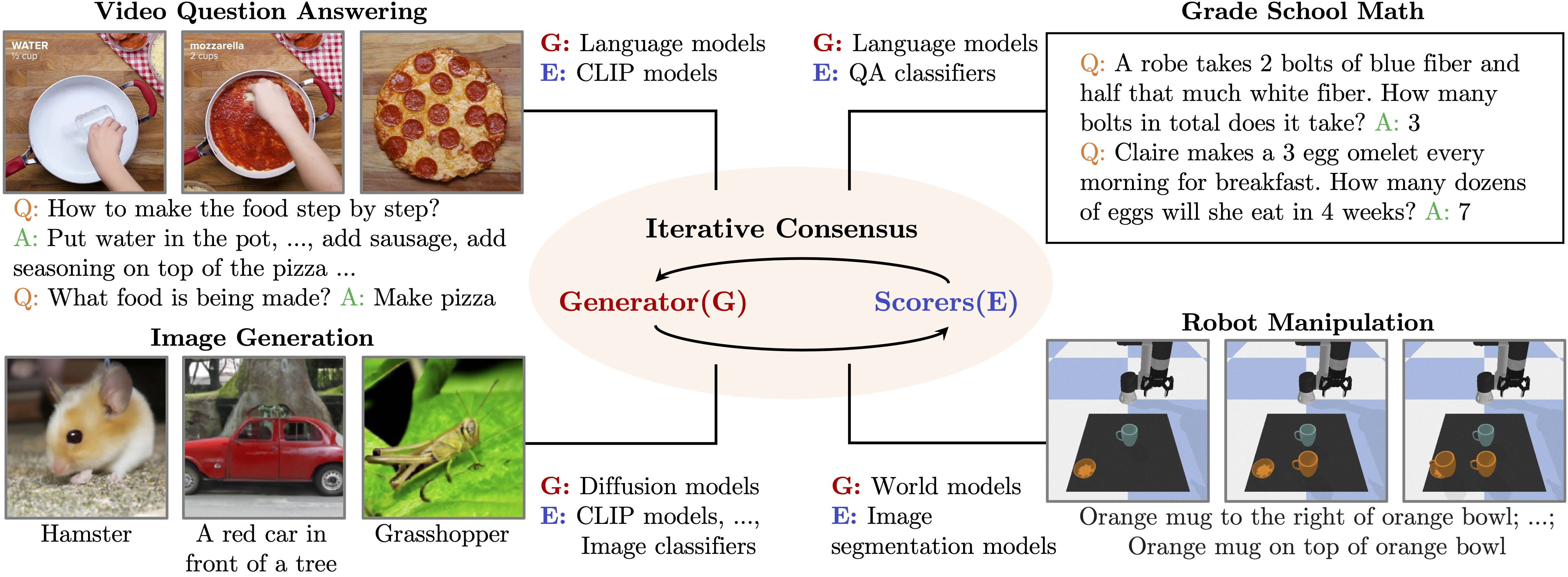
Overview of the proposed unified framework. Dashed lines are omitted for certain tasks. Orange lines represent the components used to refine the generated result.
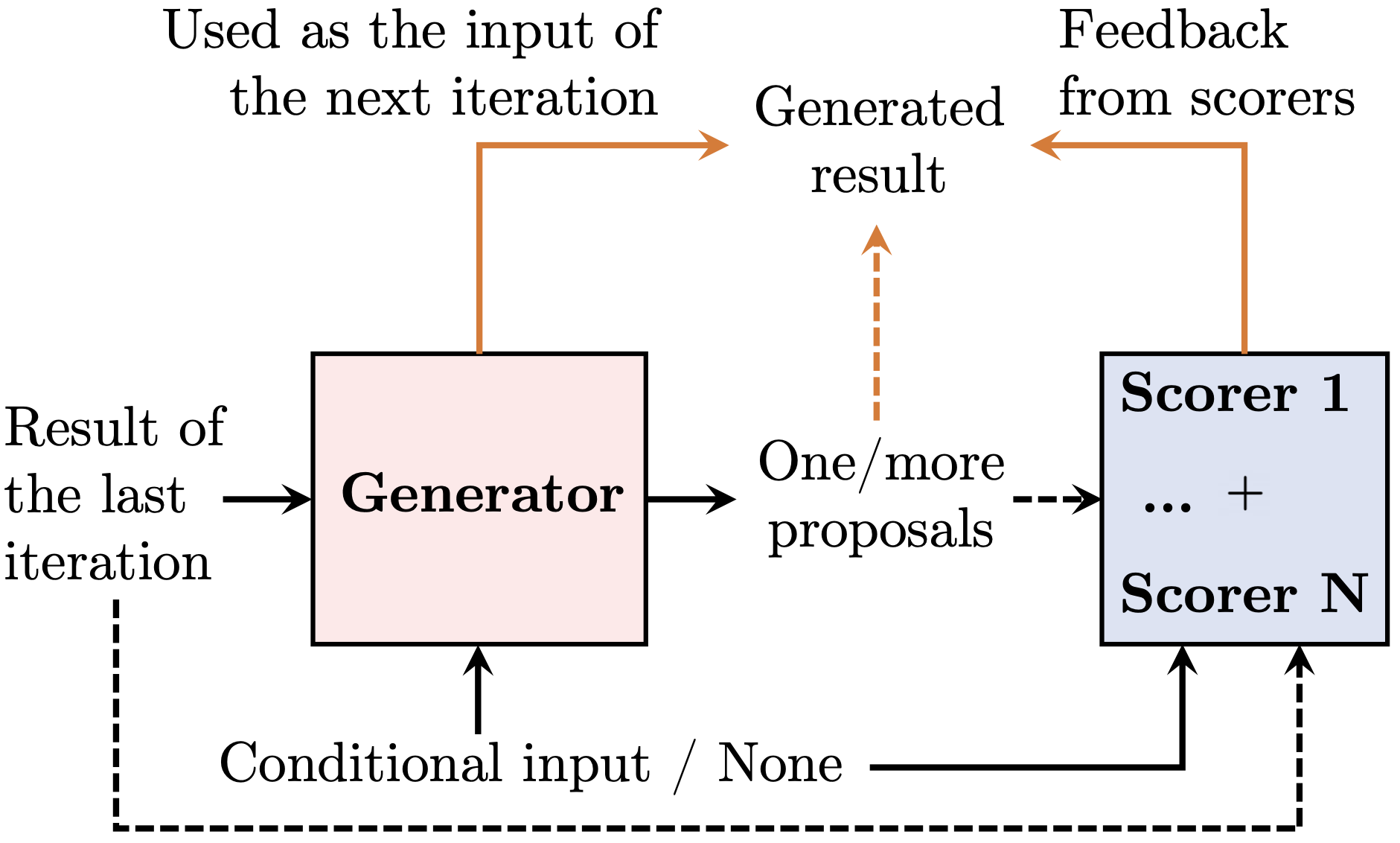
Image generation: A pre-trained diffusion model is used as the generator, and multiple scorers, such as CLIP and image classifiers, are used to provide feedback to the generator.
Video question answering: GPT-2 is used as the generator, and a set of CLIP models are used as scorers.
Grade school math: GPT-2 is used as the generator, and a set of question-solution classifiers are used as scorers.
Robot manipulation: MPC+World model is used as the generator, and a pre-trained image segmentation model is used to compute the scores from multiple camera views to select the best action.
Video Question Answering Results
Grade School Math Results
Image Generation
Robot Manipulation Results
Related Projects
Check out a list of our related papers on compositionality. A full list can be found here!

Team

Shuang Li
MIT

Yilun Du
MIT

Joshua Tenenbaum
MIT

Antonio Torralba
MIT

Igor Mordatch
Google Brain