Object Decomposition
Our method can decompose a set of unlabeled images from into objects without using any labels.

Text-to-image generative models have enabled high-resolution image synthesis across different domains, but require users to specify the content they wish to generate. In this paper, we consider the inverse problem -- given a collection of different images, can we discover the generative concepts that represent each image? We present an unsupervised approach to discover generative concepts from a collection of images, disentangling different art styles in paintings, objects, and lighting from kitchen scenes, and discovering image classes given ImageNet images. We show how such generative concepts can accurately represent the content of images, be recombined and composed to generate new artistic and hybrid images and be further used as a representation for downstream classification tasks.
We discover a set of compositional concepts given a dataset of unlabeled images. Score functions representing each concept $\{c^1, \dots, c^K\}$ are composed together to form a compositional score function that is trained to denoise images. The inferred concepts can be used to generate new images.
Our method can decompose a set of unlabeled images from into objects without using any labels.
Our method can decompose the kitchen scenes into kitchen range (i.e., stove and microwave), kitchen island, and lighting effects. Note that we name each concept based on attention responses for easy visualization. Hover to image to visualize attention heat maps.









































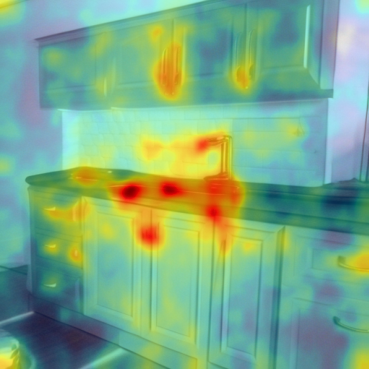

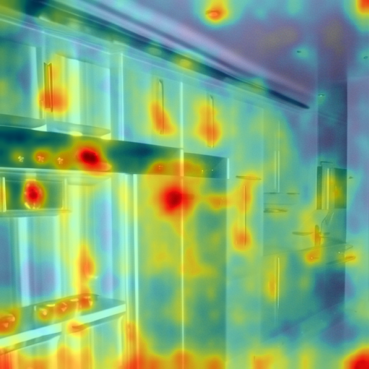



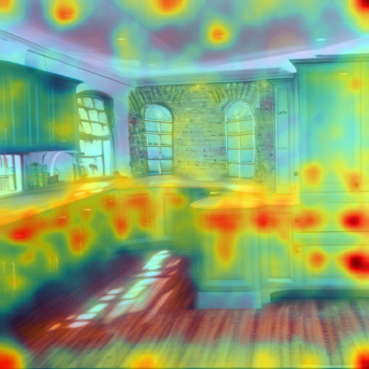
Our method can decompose paintings from artists into artistic components.

After a set of factors is discovered from a collection of images, our method can further enable compositional generation using compositional operators from composable diffusion. Note that concept names (no quotation marks) are provided by us for easy understanding since we discover concepts without knowing the labels.


@InProceedings{Liu_2023_ICCV,
author = {Liu, Nan and Du, Yilun and Li, Shuang and Tenenbaum, Joshua B. and Torralba, Antonio},
title = {Unsupervised Compositional Concepts Discovery with Text-to-Image Generative Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {2085-2095}
}