Method
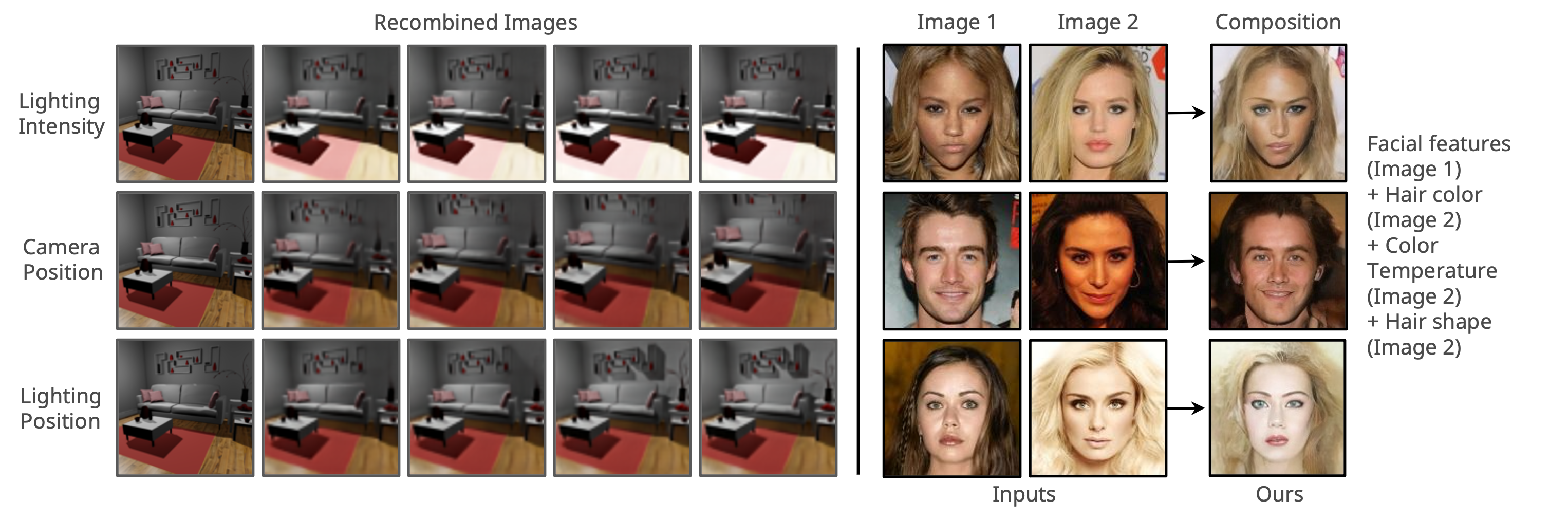
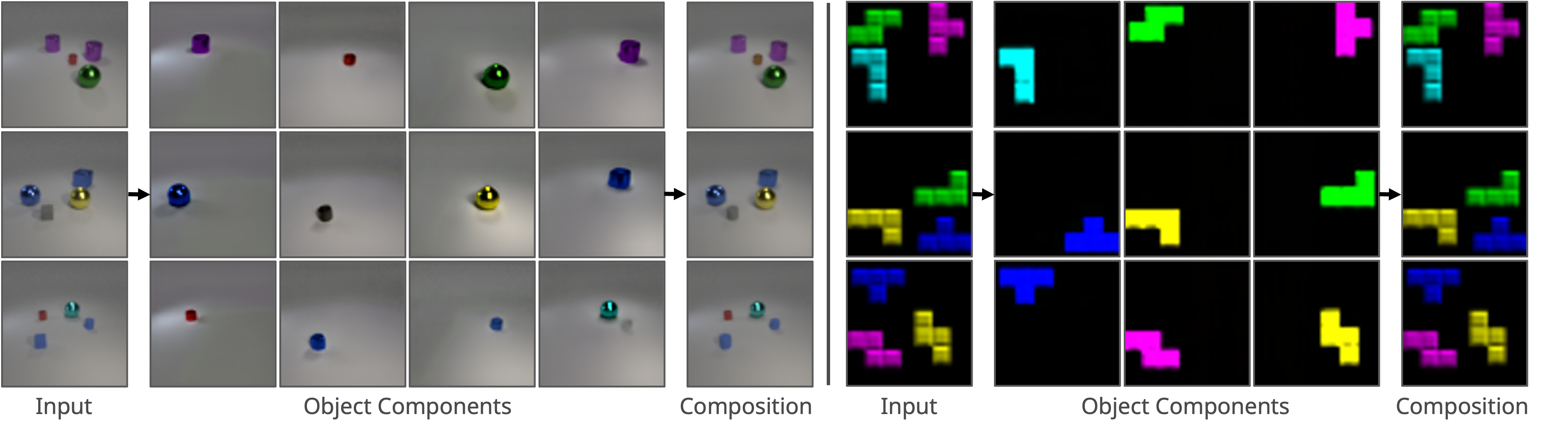
Decomp Diffusion is an unsupervised approach that discovers compositional concepts from images, which may be flexibly combined both within and across different image modalities. In particular, it leverages the close connection between Energy-Based Models and diffusion models to decompose a scene into a set of factors, each represented as separate diffusion models.
Our method decomposes inputs into $K$ components, where $K$ is a hyperparameter. We learn a set of $K$ denoising functions to recover a training image $\boldsymbol{x}_0$. Each denoising function is conditioned on a latent $\boldsymbol{z}_k$, which is inferred by a neural network encoder $\text{Enc}_\theta(\boldsymbol{x}_0)[k]$. Once we train these denoising functions, we use the standard noisy optimization objective to sample from compositions of different factors.
Demo
We illustrate our approach's ability to decompose images into both global and local concepts, as well as reconstruct the original image by recombining concepts.
Click on an image to view its decomposition and reconstruction. Hover over a decomposed component to view its description.